The PIs are working on the following projects to develop, advance, and improve the ENKi Portal infrastructure.
Who |
Projects |
|---|---|

Mark S. Ghiorso |
Automatic code generation - Developing software tools to automatically generate computer code that implements thermodynamic models. Built using SymPy, the tools allow user specification of a model for the zeroth order energy function of a phase (e.g., Gibbs free energy, Helmholtz energy) in general symbolic terms. These symbolic expressions are automatically differentiated by SymPy, which then generates computer code to implement the model and to recover all thermodynamic functions and (if a solution phase) their compositional derivatives. Both C and C++ code (the latter thanks to the efforts of Owen Evans) may be created, but any standard language implementation can be output as long as templates are provided. Code is generated for two cases: (1) Production code with embedded parameters for rapid calculation of properties, and (2) Calibration code with modifiable parameters (and parameter derivative functions) for calibration of models. Currently, automatic code generation modules are available for the Berman pure phase model and for simple solutions (3rd order Margules-type formulations). Work is underway on solution models with internal ordering parameters or speciation. Configuration of ENKI compute server - Configuring the ENKI compute server, including writing software libraries and JupyterLab extensions. The ENKI compute server is a JupyterHub server running single-user instances of JupyterLab. (The physical server is a quad-core Mac mini.) ENKI software libraries, which are written in Python, R, C, FORTRAN, C++, and Objective-C, are implemented on this server and are accessible via Python and R wrappers to use in standalone scripts and Jupyter notebooks. ENKI-tailored site functionality is achieved using JupyterLab extensions; three of these extensions (jupyterlab_enkiintro, jupyterlab_gitlab, and jupyterlab_shared) are available on GitLab and on npm. Additional extensions under development will implement functionality to access code repositories and will provide tools that address reproducible workflows. Model calibration infrastructure - Assisting Aaron Wolf with design of software infrastructure for thermodynamic model calibration. The calibration code is based on a Bayesian model and relies upon the following:
Algorithms for generalized equilibrium calculations - Extending computational thermodynamics algorithms to devise generalized equilibrium calculators applicable to open systems. Equilibrium in heterogeneous systems is usually calculated by specifying fixed bulk composition and either temperature and pressure, entropy and pressure, enthalpy and pressure, volume and temperature, or entropy and volume. Occasionally the procedures are extended to open systems to account for externally fixed chemical potentials. In this project, computational thermodynamics algorithms are extended to devise generalized equilibrium calculators applicable to open systems with any number or combination of fixed external chemical potentials. Implementation and documentation for this project is in the form of Jupyter notebooks. Infrastructure architecture - Designing the user interface to the ENKI compute server and (with Carla Johnson) creating website content. Responsible for software architecture (with Aaron Wolf). MELTS - DEW algorithms - Improving the algorithms for MELTS - DEW connection. The ENKI compute server is the host platform for software and Jupyter notebooks that implement the addition of the Deep Earth Water model (DEW) to the MELTS data/model collection. The goal of the project is to examine elemental partitioning between magmas and aqueous solutions. Part of this effort has been the generation of a code base for the HKF aqueous standard state model and a new interpolative algorithm for pure water properties generated from a combination of reference state models, which is known as the Standard Water Interpolative Model (SWIM). Currently, the DEW fluid speciation algorithm is being improved to speed up computations. Code libraries for standard databases - Standard thermodynamic databases are coded and available in the ENKI software library, including the database of Berman (original and as extended by MELTS), Holland and Powell (pure component properties), Stixrude-Lithgow-Bertelloni, and Helgeson et al. (SUPCRT). Additional databases are planned to be added including Holland and Powell solution properties and the database of Jacobs. Data entry for recalibration effort - Accumulating literature data on experimental phase equilibria and fundamental measured thermodynamic quantities that form together a database for calibration of thermodynamic models. This project is related to the model recalibration effort. Our current project, led by Aaron Wolf, is to assemble literature data to reproduce the calibration of the Berman database. Publication of Jupyter notebooks - With the Deep Carbon Observatory and the American Geophysical Union, establishing a refereed journal publication pathway for papers written as a single Jupyter notebook or as a collection of notebooks. Background: A principal means of building models with ENKI is to access software resources from Jupyter notebooks. Such notebooks embody a complete record of the modeling effort, can be executed to duplicate results, and can be documented to detail the logic behind the computation. Historically, the notebooks themselves have no direct avenue to publication. They can be attached as static supplementary documents to standard publications, but that prevents replicating or extending the analysis. Access to the full notebook and the software ecosystem underlying notebook execution is desired. Helgeson textbook - Digitizing (with Carla Johnson) Theoretical Geochemistry, an eight-chapter, previously unpublished textbook by Hal Helgeson. The textbook will be available as intereactive Jupyter notebooks. Workshops - Organizing ENKI workshops along with Diane Catt, who handles planning and logistics. Workshops are opportunities to utilize the ENKI user group to vet modeling capabilities and evaluate interface design and software libraries. The next ENKI user workshop is planned for late July at the Tamaya Resort (Santa Ana Pueblo, NM). An additional workshop targeted to early career scientists will precede the Goldschmidt meeting August 2018 in Boston. Outreach - Responsible for selecting and managing the ENKI user group and for organizing ENKI-related activities at national and international meetings. Currently planning ENKI activities at the upcoming Goldschmidt meeting (Boston, August 2018) and AGU meeting (Washington, D.C., December 2018). Other outreach activities involve creating software documentation and YouTube videos (with Carla Johnson). |

George Bergantz |
Currently our ENKI efforts are directed at developing tools for thermodynamics based post-processing of large scale DEM-CFD (discrete element method-computational fluid dynamics) and CFD simulations. This has been broken down into three efforts, the outcomes of which are Jupyter notebooks. The three efforts are complementary in that they both involve the notion of populations, and so produce data objects amenable to the kinds of statistical analysis that has not been possible previously in petrology.
|

Peter Fox |
Fang Huang, Feifei Pan, and Patrick West are working on the following projects:
|

Everett Shock |
Jupyter notebook tools - Grayson Boyer has developed Jupyter notebook tools for the automation of geochemical data cleanup (charge balancing, etc.), and calculation of water sample chemical properties including speciation and mineral saturation states. These tools, built on the EQ3 code, automate complex quality control calculations for environmental water samples, reducing task time from weeks to moments and allowing easy statistical post-analysis of results. He is working to optimize the use of these notebooks for data mining of results from thousands of output files, taking advantage of ongoing projects by other members of Shock's research group (GEOPIG) who have extensive sets of geochemical analytical data. Grayson is also building notebooks to help with estimation of thermodynamic properties of membrane lipids using predictive tools developed in his recently defended PhD research. He is considering an offer of a post-doc position in GEOPIG to expand his use of data science tools to manage geochemical data and to generate and interpret results of speciation calculations. Python software - Tucker Ely has developed Python code to manage thousands of simultaneous reaction-path calculations using the EQ6 code, as well as DBCreate and Supcrt. He is working with other members of GEOPIG to automate thousands of water-rock calculations for seafloor, continental, and extraterrestrial hydrothermal systems. In addition, Tucker is refining software in Python that takes fluid compositions (environmental or experimental) that exhibit redox disequilibria, and returns an inventory of the energy supply that can support microbial metabolism. This will allow researchers to see rapidly the rank-ordered energy profiles for 100s of redox reactions across 1000s of fluid samples. Results will be available as affinities per mol of electrons transferred, or energy per milliliter of fluid, and other variants on units. |

Marc Spiegelman |
Software design for transparent and reproducible thermodynamic modeling - In a central collaboration with Mark Ghiorso, Aaron Wolfe, Cian Wilson, and students Owen Evans and Lucy Tweed, we are developing a software framework for the creation and recording of custom, reproducible thermodynamic models for use in a range of workflows including calibration (Wolfe), optimization and phase equilibrium (Ghiorso), and incorporation in high-performance disequilibrium geodynamics models (Spiegelman). The software design is similar to that developed for TerraFERMA, where the user records all choices for variables, parameters, and functions for general thermodynamic potential models of endmembers, phases, and reactions in a hierarchical xml schema (using the SPuD libraries and gui), which are then used as input to SymPy-based code-generation code for construction of custom compiled (C or C++) libraries with Python bindings for use in a wide range of thermodynamic workflows. Integration of computational thermodynamics and computational geodynamics - Spiegelman's primary goal in this project is to use the thermodynamic modeling software to develop high-performance, custom libraries for integration in open-source geodynamic modeling code including TerraFERMA and other large scale PDE-based codes such as CIG's Aspect. Specific tasks include:
|
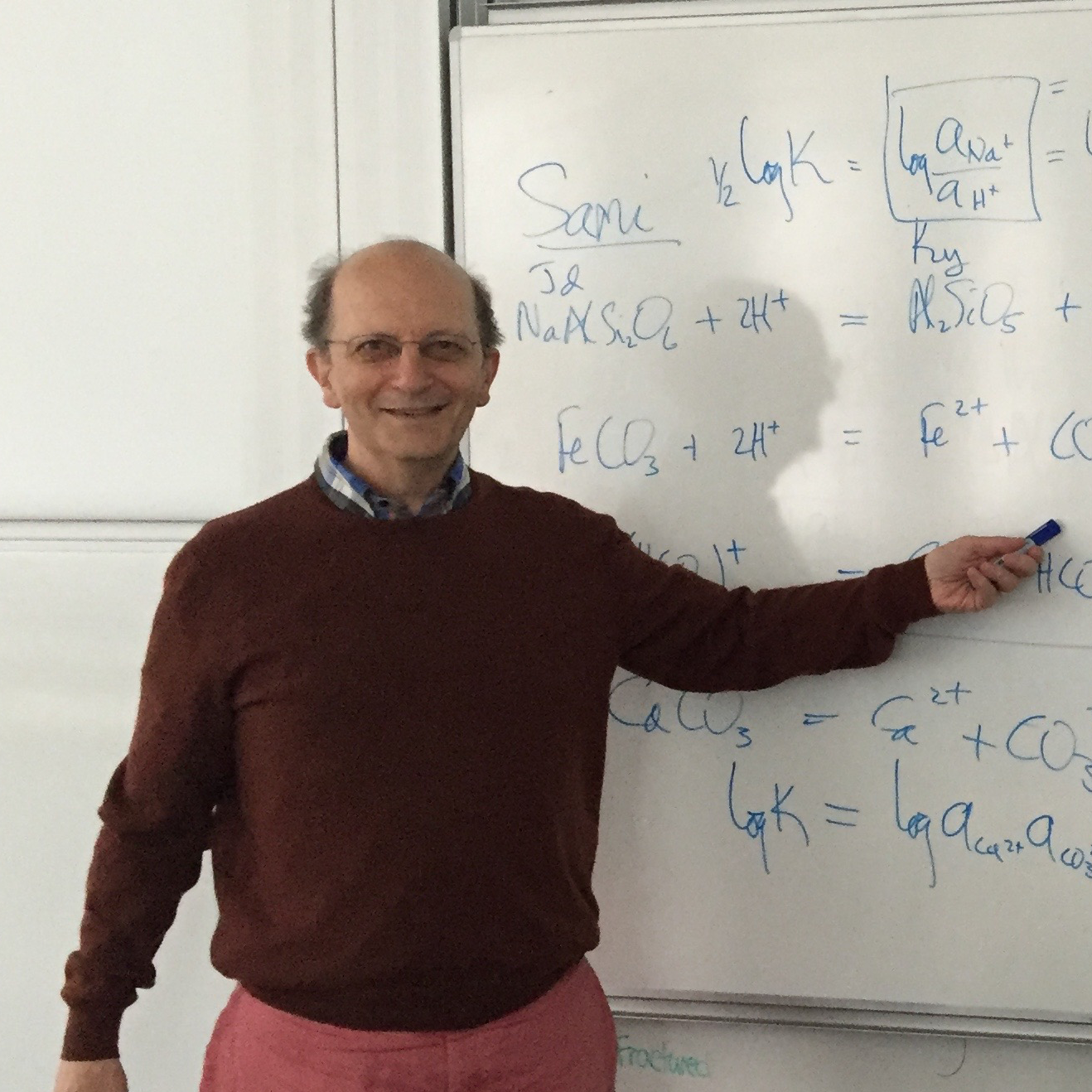
Dimitri A. Sverjensky |
Developing thermodynamic characterizations of the standard state properties of CO2 and H2CO3 as functions of temperature and pressure that are consistent with available solubility and ionization data. From an ENKI standpoint, a goal here is to be able to use the standard state properties to reinterpret the Aranovich and Newton (1999) CO2-H2O activity model in terms of CO2-H2CO3-H2O species that are linked to the thermodynamic properties of the minerals derived in the ENKI project. In other words, we could show how the revised properties of the minerals feed into the retrieval of experimentally derived activities of CO2, H2CO3, and H2O. A result would be a new model for the activity concentration relationships of CO2, H2CO3, and H2O. Dimitri Sverjensky is working on this. Demonstration of the retrieval of the thermodynamic properties of NaCl-H2O solutions from experimental measurements of densities as functions of temperature and pressure. A goal here would be to develop the software that will be also usable for other salt solutions for which experimental densities have been measured at high temperatures and pressures. Graduate student Jingyi Huang is working on this. |

Aaron Wolf |
Calibration - A major part of the ENKI project is concerned with the development of new thermodynamic models for minerals and melts. This task involves the development of new techniques for calibration, implementing these methods within easy-to-use Python software, and applying them to describe geologically relevant compositional systems. These efforts are moving forward through the combined efforts of co-PI Wolf together with PIs Mark Ghiorso and Marc Spiegelman and graduate students Jenna Adams and Lucy Tweed. The calibration efforts as a whole are spread across a set of interrelated projects:
Design of Python libraries - Together a core group of the ENKI team members have worked to implement an extensible and maintainable code base for the ENKI project. These include Aaron Wolf, Mark Ghiorso, Marc Spiegelman, Lucy Tweed, and Cian Wilson. The top-level code is built primarily in Python and distributed as the "thermoengine" package, which is designed to provide tools for a variety of use-cases including:
Thermoengine provides a set of modules to accomplish these goals, including modules for modeling thermodynamics of individual phases, reactions, and entire thermodynamic databases (like MELTS). It also includes calibration modules, including storage and handling of experimental phase reaction data, the definition of calibration model families (in terms of priors and posteriors for model parameters), as well as actually performing the model-fitting to obtain the calibration (including storage of complex multi-step calibration procedures). Modules are written in clean Pythonic format, utilizing standardized numpy/scipy style docstrings to improve understandability for the users. We have also begun to implement principles of continuous integration, including automatic documentation building using Sphinx and Gitlab. This code base is designed so that the package is relatively implementation-agnostic, and thus our efforts to migrate toward automated code-generation will be able to immediately substitute into the Python code, replacing the current Objective-C thermodynamic computation core. Database construction - Thermodynamic database calibration requires direct access to all of the experimental data that the model is built upon. We have thus begun building a comprehensive database of experiments, which includes not only the standard data (e.g. pressures, temperature, compositions, etc.) but also considerable additional meta-data. These meta-data include important information like the presence or absence of additional phases, sample preparation details, and the degree of the observed reaction progress. All these data are important for our novel calibration procedure, as well as potential filtering of the dataset to enable the future creation of specialized databases. All this work is organized in our "geothermodat" Gitlab repository. To enable these efforts, we have designed an extension of the LEPR (Library of Experimental Petrology) database format that can accommodate these new data requirements. The format is implemented in excel for user-friendly entry for all members of the geochemistry/petrology/geophysics community. In addition to implementing convenient input/output options for excel, we adopt an internal storage approach using the simple JSON text-file format. By storing the data in flat text files, the database itself remains software agnostic, insulating this work from any future changes made to the excel file format (in future, we could expand to allow input/output in formats other than excel). To support this work, we have created a number of tutorial videos, available on youtube, as well as created validation tools to help users check and visualize their data input files, ensuring that they are complete and correctly filled out. Ongoing work on the database is enabled through the geothermodat repo hosted on Gitlab. Collaborative tools provided by gitlab, including wikis, user-submitted issues, and milestones, enable volunteer participants to coordinate activities in digitizing published experimental data. As a first major milestone, we are working on digitizing the pure (stoichiometric) phase data underlying the Berman(1988) thermodynamic database. Though time-consuming, these issues are critical to the success of the ENKI project and once complete, this digitization work will never need to be repeated since all our efforts are open source. At that point we can shift to maintaining the database by adding newly published material. |